Frontier labs train for everyone.
That works for broad assistance. It breaks down when the business need is specific, high-context, and hard to prompt.
Make LLMs think better. Make them write better. Keep them from losing what they already know.
Lala Labs helps enterprises that want their AI to be more than just acceptable.
We work at the level where models actually operate: language, reasoning, style, inference, and context.
The goal is simple: smarter models, clearer outputs, fewer tokens, less prompting, and less lost capability between training runs.
That works for broad assistance. It breaks down when the business need is specific, high-context, and hard to prompt.
RAG, prompts, fine-tunes, harnesses, and RL environments keep models in check. They do not help the models understand the work.
We measure what the model misses, then build systems that improve the text, the reasoning, and the signal density.
Products And Services
Built for teams that need proprietary knowledge, reliable outputs, and model improvement that can actually perform real work.
Advisory And Implementation
Pre-training and post-training advisory, RL environment design, RAG optimization, and full-stack LLM deployment support.
Training loops tailor-made for your business needs.
Model behavior tuned to your market, product, and customers.
LALA Benchmark
Custom evaluation systems that map model competence across context, style, inference, clarity, and enterprise-specific goals.
Fewer words. More signal. Less compute.
Language Systems
Semantic Analysis Matching for enterprise knowledge. Ensures models understand the nuance of your domain so that outputs mean what they should mean in the right context.
AI-to-human text generation for natural, usable writing. Turns machine output into clearer language that sounds too human for humans--and for AI detectors.
A Text Analysis Dashboard for AI output. Reviews clarity, style, tone, rhetoric, and audience fit before the text reaches production.
Consulting and Advisory
Not sure where your AI is failing--or not sure if you should bother with AI? Give us a call.
Enterprise Solutions
Lala Labs builds AI systems that understand the work, preserve the nuance, and deliver cleaner text with less prompting.
Plan a model auditBefore: verbose, generic, brittle.
After: concise, specific, goal-aligned.
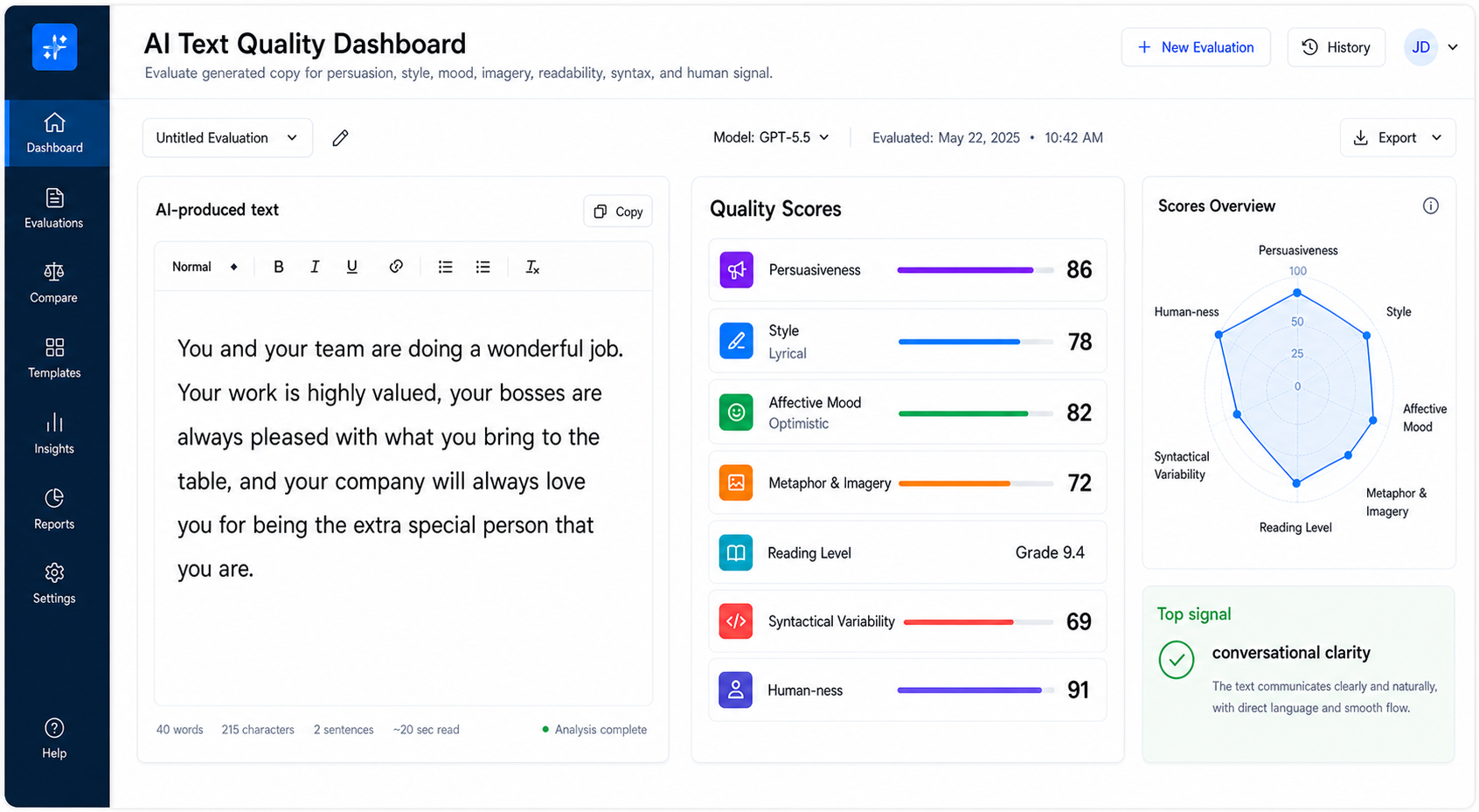
Research
We go beyond measuring if a model is "good" or "bad" to show you the multiple dimensions of LLM performance, and the tradeoffs being made through AI optimization. We identify what a model can do, and what post-training is forcing it to do.
A high score can come from real reasoning or from post-training pressure. Enterprises need to know the difference.
Base models, open models, and public models behave differently because they are shaped differently.
Better enterprise AI starts by asking what semantic content disappears before the model writes a word.
Model Classes
Different models carry different training histories. The benchmark treats them that way.
Work With Lala Labs
Start with an audit. Leave with a clearer path to smarter models, better text, and more durable enterprise AI.
Contact Lala Labs